

Wait, there's more than Google?
Yes, there's Bing. Just saved you from going to a large tech site and thumbing through 5-10 pages of ad-sponsor hell while they divide up the list to 10 pages in a desperate attempt to improve clicks.
And Yahoo, I guess? That's all.
You're welcome.
Seriously, we can't tell you how many times we've seen the article "Top 10 Search Engines" from countless bloggers, only to find out that if you are in an English-speaking country. You pretty much have different flavors of Google dominating %80 of the market (Duckduckgo, Presearch, SearX, AskJeeves, and the list goes on, where they mindlessly accept either a Google or Microsoft aggregate instead of doing the hard work themselves.) Beyond that, there is Microsoft Bing with their %8, and finally, Yahoo is still hanging in there with their %2 of total internet searches.
Where do these percentiles come from? Like other bloggers, we pulled those percentiles out of thin air! But it sure as hell feels that way!
Would you like to know more? Read onward
Preface
Now, we're going to state that this article may be small at first. Because we want you to leave a comment below and tell us about different search engines as well. We're straight-up curious! Now, we're not going to include any site that simply aggregates from the big three(Google, Yahoo, Bing).
We are also aware of other search engines like Yandex and Baidu. They have their own monopolistic tendency over their own countries and will not be listing them either, as well as happily censoring their engines for government compliance. Nor will we be including archive/wiki sites, as archival sites take away traffic from independent sites. Now, unlike my Video search engine article, we can't easily do a side-by-side comparison because each site is unique. This is actually good! Because it means that none of them are really drinking the same Google/Microsoft Kool-Aid as pointed out in that article.
Let's begin.
Onward to the list.
 Marginalia
Marginalia
This will take you to the home page of what appears like a hyper developer site until you go to the search. Suddenly it opens up stating that it's an independent DIY-based search engine that focuses on non-commercial content. We discovered this on the forum where a user stated that it favored text-heavy sites while punishing modern web design.
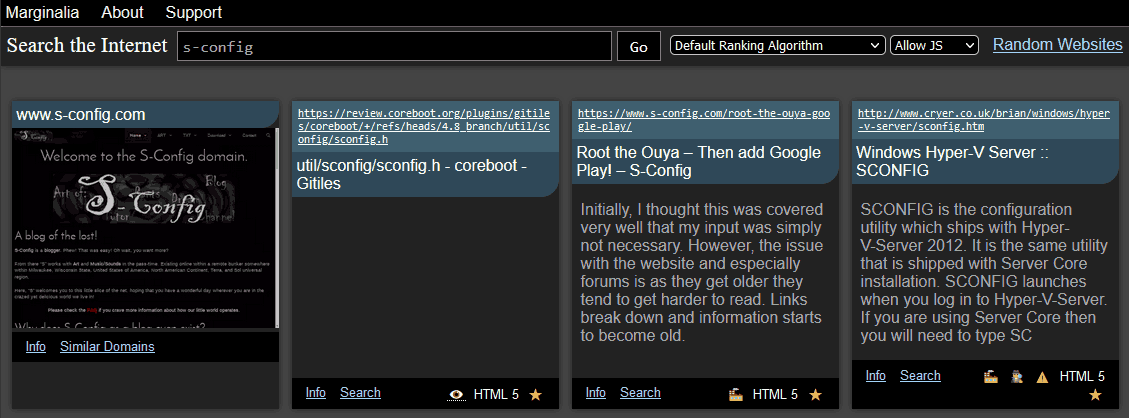
We were moderately surprised to see our domain right there. Indicating that they are forgiving when it comes to JavaScript and modern design (or perhaps we were text-heavy enough) We also really dig the icons on the lower portion of each result, indicating what technologies the site uses and any warnings. As for ours, it shows there are scripts running, which is absolutely true. As a WordPress blog, we can't turn off JQuery.js. It does terrible things when you remove it.;)
Update note: we switched to ClassicPress, and a lot of this has been resolved.
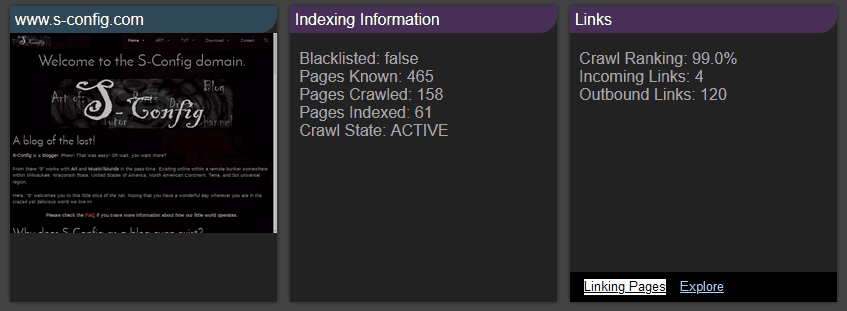
We especially dig the info of the domain showing what their spider has done. Really fucking cool!
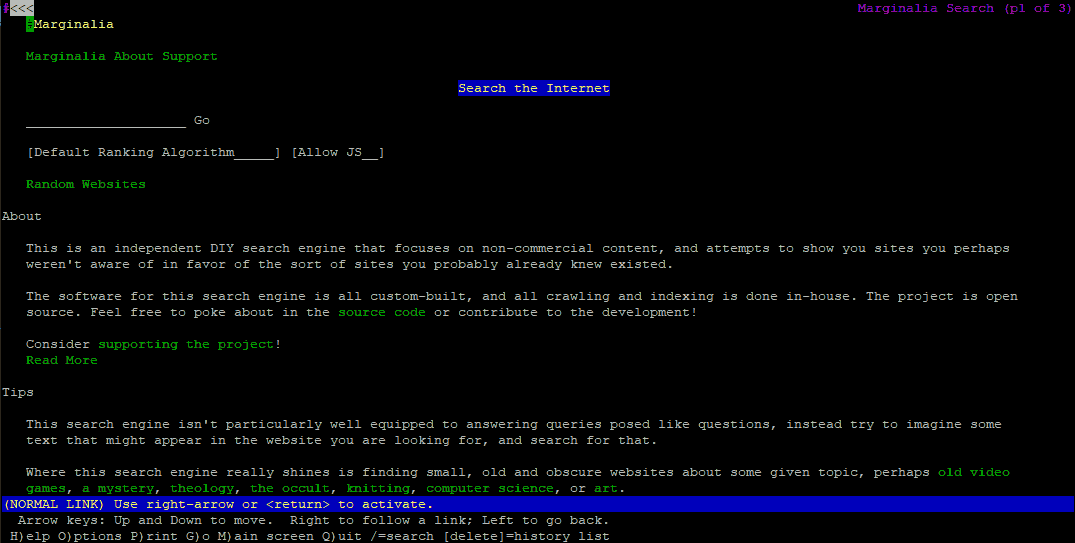
May we also comment on how absolutely sexy this website looks in LYNX?!?
Now, for those younger readers checking out this article. Lynx was a way for people on shell accounts (text-only terminals ) to look up HTML websites. To use a PC or MAC with color graphics as we take for granted today was often reserved for 'premium' workstations that libraries and universities had in the 90s. Time was limited per student on those systems. But there was no limit on the text terminals, as the bandwidth was so inherently low it did not affect the Frame Relays and ISDN modem 128Kbs (or if you were a REAL high roller, T1 @ 1Mbs up and down) bandwidth these institutions had. Finally, you should visit his support page and donate to him if you find his site useful. Give the developer a few bucks. They sure as hell deserve it!
 Wiby
Wiby
Wiby has a different philosophy of being the search engine for vintage computers to use. And by default, this site takes you to websites that were coded with some of the simplest HTML out there.
Understandably, you will not find our site here. We have FAR too much JavaScript combined with an SSL that does not easily let machines from the 1990s browse around my site.
Update:
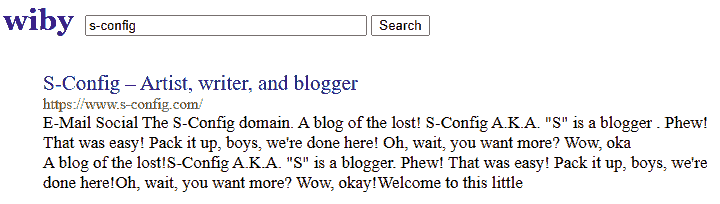
We think it's a tad narcissistic to look up your own site, too.
The reason why Wiby couldn't easily index us is that our SSL TLS security restrictions were for modern computers. After a bit of de-thinking from Google. We presented to Wiby a standard http addressed site, and it seemed to like it. Later on, it seemed that Wiby accepted our HTTPS site naturally. Odd. The site's meta gets a little tripped up on my header possibility due to the crazy CSS we did. But still, very happy we even showed up there!
The randomized feature is like being taken on a roller coaster into the 1990s of websites. Where it's not just focused on small web designers, but in particular the older way that machines from the 1980s and 1990s can understand. Which could very well be notepad.exe and a lot of time with HTML. Also, note that it gives you instructions on how to build your very own search engine, like Wiby, for your own personal applications. The best search engine security is starting your own search engine after all!
 Brave Search
Brave Search
We have a very hard time keeping Brave on this list because Cryptobros often lie about their tactics. So take this suggestion with whatever grains of salt you want.
Akin to the browser, Brave claims to be privacy-oriented and able to be completely independent of other search engines. Unlike the others mentioned at the beginning of his article, if the three big tech companies were to die. Brave would be totally fine. At least according to their FAQ.
We took a look at Brave back when we did the grand Google Video Monopoly, and like a lot of the bigger search engines, asking a question as to how their video search results worked led to silence for the most part.
However, it does seem like they're quietly improving things, as quotations didn't work a few months back, allowing a person to specify exact words in a search for something, as we did with our domain. This is by far bigger than the previous three search engines out there.
We're reluctant about Brave as it claims to be independent, but it's incredibly hard to verify this, as the company often keeps quiet on even the things they fix, let alone the things people are having a problem with. However, if you are looking for a bigger, broader range search engine that isn't Google. Brave would probably be the best go-to search engine on this list.
 Yep Search
Yep Search
We're somewhat reluctant to include this on the list because this company, known as "Ahref'" has been spidering since 2010 for their SEO business. Anyone who has read my articles knows how much we despise SEO scalpers. However, since we mentioned Brave earlier, it wouldn't be fair not to include Yep on this list too.
The appeal of the Yep search engine is that it's supposed to find 'relative' search results as well as the absolutes. It found our ancient Twitch profile, but didn't really find any of the other profiles that are floating around out there. Now, you see that widget down below? It's almost as if Yep isn't confident in its own search results and instead insists that you, the user, give up on them and just use Google/Bing/Mojeek/DuckDuckGo(which is a scraper of Google) instead.
To that end. Yup is probably at the absolute bottom of the list. Use Yup if you have no other choice and you still want to get away from the big tech engines.
Final thoughts.
Every engine mentioned in this article has its own crawling mechanism (presumably, we don't work at their offices or know for a fact). This is incredibly important in the age of information manipulation. We have to question if the political alignment or the advertisement interests of Google/Yahoo/Microsoft overshadow its ability to be an impartial search engine. Both companies practice search engine manipulation, where they want you to explicitly stay on their site.  Even if it means stealing data from other sites or implementing open-source widgets from other developers in an effort to keep you, the end user, from clicking away. Once again, this is where Google becomes its own worst enemy. A search engine that never wants you to find a webpage with said results. All of this is calculated and manipulated.
Even if it means stealing data from other sites or implementing open-source widgets from other developers in an effort to keep you, the end user, from clicking away. Once again, this is where Google becomes its own worst enemy. A search engine that never wants you to find a webpage with said results. All of this is calculated and manipulated.
 Valid reasons to turn off RSS feeds.
Valid reasons to turn off RSS feeds.
We wish we could give you a better solution for search engines. But the truth is, spidering the net to cross-check sites takes money, time, and often a defensive stance, as not even Google can handle the constant onslaught of websites sealing RSS from others.
A lot of this, unfortunately, does come down to money because it takes money to run a data center to collect the data to give to you, the end user. As the tech industry has gotten society accustomed to not paying for a search engine. It almost locks out any and all competition in the upstream.
With the death of DMOZ, the last human-editable search engine. Human-edited sites are a practice that is necessary on onion services because of engine manipulation. There is absolutely no checksum for a large corporation to push the engine in a certain direction. It's just one algorithm versus another algorithm. Combine this with the simple fact that Google "gives up" after 1,000 entries. We have no clue what Google is even indexing. Or if those 91.8 million results pictured above are even real.
The bottom line: Using another engine can be an adventure. And it's worth it!
That's what server said.
+++END OF LINE
What happened to Gigasearch (which you mentioned in a previous version of this writeup)? They go out of business? It's been MIA for over a month.
It's like they were here-today-gone-tomorrow.
I think you meant Gigablast. To answer the question? Unknown! Their Partner Freenode also is unresponsive as well. It's like someone zeroed their rack at the data center without informing no one.
i'm a big fan of kagi, although they are subscription based, the money you spend on that search engine gives you some peace of mind that your wallet is their revenue rather than your data. they also prioritize in quality over quantity (of results). there have been many situations for me in which kagi has given me better results than google or ddg. it also supports bangs, like !yt or !g.
Didn't know about Kagi at first, but we did go through their FAQ.
The problem with Kagi is that it relies on the aggregate of other APIs and search engines instead of going out and finding its own data. Suppose Google for example wipes this domain off of the face of the earth. Kagi would probably resort to Bing and Teclis for further validation. But when it comes to other blogs or starting websites they may not be so lucky to be mirrored throughout the entire eco-sphere of the internet. Kagi effectively does with an open source software SearX does. Acting as an anonymizing aggregate with the bonus feature of personalized promotion and demotion of sites. I couldn't put SearX on this list because it misses the core aspect of a search engine which is the ability to spider and aggregate its own data. Unfortunately, Kagi also falls into this category as well. A service that is relying on other services telling the truth.
Thanks for the response. take care out there.
- S